Искусственный интеллект точнее диагностирует в условиях приемного отделения: роль врачей становится лишь важнее.
В приемное отделение поступает пациент с одышкой и анамнезом тромбозов. Врачи видят неэффективность антикоагулянтной терапии, корректируют лечение, наблюдают. Модель искусственного интеллекта, анализируя ту же электронную медицинскую карту, замечает нечто, упущенное людьми: у пациента, как сказал бы доктор Хаус, системная красная волчанка, что кардинально меняет картину, поскольку воспаление легких оказывается не тем, чем казалось на первый взгляд.
Этот случай является одним из 76, проанализированных командой Гарвардского университета и медицинского центра Beth Israel Deaconess в исследовании, опубликованном на прошлой неделе в журнале Science. Это одно из самых строгих на сегодняшний день исследований, сравнивающих крупномасштабные языковые модели (LLM) с врачами в реальных условиях приемного отделения, и оно содержит несколько примечательных моментов.
Почему именно при первичном осмотре (triage)?
На этапе первичного осмотра вы находитесь в точке максимального давления, с наименьшим количеством информации и наибольшей срочностью в постановке диагноза для определения дальнейшего пути лечения; по сути, это момент, который, как правило, является хаотичным.
В этой ситуации модель o1 от OpenAI идентифицировала правильный или очень близкий диагноз в 67% случаев, в то время как опытные врачи, выступавшие в качестве контрольной группы, достигли 55% и 50% соответственно.
И этот разрыв в 12-17% в самый хаотичный момент оказания медицинской помощи является той частью исследования, которая мне кажется по-настоящему важной. Он точно указывает, где и как этот инструмент должен быть интегрирован и превращен в отличного "второго пилота".
Проблема с вопросом, который мы задаем
Каждый раз, когда появляется подобное исследование, медиа-приманка фокусируется на заголовках типа "ИИ заменит XX", где XX — это врачи, участвовавшие в исследовании на этой неделе; врачи говорят "цифры меня не убеждают", и все заканчивается ничем... тогда как ключевой вопрос заключается в следующем:
в какой конкретный момент клинического процесса хорошо реализованная модель снижает ошибки, которые стоят жизней?
И исследование, если прочитать его внимательно, довольно точно отвечает на этот вопрос, поскольку преимущество модели o1 было наиболее выражено именно при первичном осмотре (triage), потому что именно там у врача меньше информации, больше временного давления и выше вариабельность качества принимаемых решений.
Однако при наличии большего количества данных (на момент госпитализации) разница сократилась: 81,6% для o1 против 78,9% и 69,7% для врачей; то есть, статистически незначимо.
Что это означает? Что ценность модели как "второго пилота" выше там, где человеческая система наиболее напряжена, а не там, где она лучше всего подготовлена.
Идеальный "второй пилот"
Обратите внимание, что есть интригующая часть исследования, которой мало кто уделил внимание: в случаях так называемых "непропускаемых диагнозов" (где ошибка может стоить жизни), модель также не показала статистически значимого улучшения по сравнению с врачами.
Для меня это очень важно, потому что именно в тех ситуациях, где больше всего требуется надежность системы, ее преимущество исчезает... и это, на мой взгляд, усиливает аргумент в пользу концепции "второго пилота".
Модель может быть превосходна для расширения дифференциальной диагностики, для выявления случая системной красной волчанки, который упустил уставший врач, для систематизации рассуждений в сложных случаях, когда внимание врача может быть "отвлечено", но это не безошибочная система безопасности в худших сценариях.
Есть еще одна цифра, которую стоит рассмотреть в перспективе. Исследование в журнале Nature Medicine, опубликованное до этого, оценивало ChatGPT (от того же производителя, но другая модель) в экстренных ситуациях и обнаружило, что он недооценил серьезность состояния в 52% случаев. Пациенты с риском диабетического шока или дыхательной недостаточности были направлены на 48-часовое наблюдение.
Две модели одной лаборатории. Диаметрально противоположные результаты. Изменяются модель, контекст, реализация.
Вот что хорошо подытожили авторы исследования в Science: модель o1 с контролируемым доступом к структурированным клиническим записям представляет собой "потолок" того, что ИИ может хорошо делать в медицине. ChatGPT, доступный потребителям, который вы используете на своем телефоне для консультаций по симптомам, представляет собой "пол". Расстояние между ними огромно.
Как проводилось исследование?
Что мне кажется наиболее интересным в исследовании, так это не заголовок, а его дизайн.
Исследователи не спрашивали модель: "Что у этого пациента?". Они предоставили ей роль "второго мнения" в трех предопределенных точках клинического процесса: первичный осмотр (triage), первоначальная оценка и госпитализация.
Модель выступала в роли коллеги, который читает те же записи и говорит: "Смотри, я бы также рассмотрел вот это", в рамках так называемой триадической помощи: врач, пациент и система ИИ. Целенаправленное взаимодействие в определенные моменты.
Проблема в том, что почти ни одна система здравоохранения не построена таким образом; все думают об ИИ в формате "оптимизации управления", но существует колоссальная возможность для интеграции моделей клинического мышления в реальные процессы первичного осмотра, с медицинским надзором и четкими рамками ответственности.
Это исследование показывает, что не хватает "клинических испытаний", потому что, хотя результаты o1 в исследовании надежны, отсутствуют институциональные, регуляторные и отчасти культурные аспекты... особенно в США, где почти вся медицинская индустрия сталкивается с судебной индустрией, готовой обвинить ее в "этой катастрофе".
Адам Родман, один из авторов и врач медицинского центра Beth Israel, заявил: "Медицина — это сфера высоких ставок, и у нас есть способы снизить эти риски. Они называются клиническими испытаниями". И это кажется мне более честной позицией, чем у "компаний ИИ-врачей", которые пытаются исключить врача из процесса или минимизировать клинический надзор.
И, подумайте секунду, главный автор исследования, которое показывает впечатляющие результаты, сам говорит: "это не оправдывает то", — это самый важный для меня сигнал.
Что дальше?
Скорость первичной диагностики имеет значение; в приемном отделении каждая минута, потраченная на обдумывание правильного диагноза, может изменить исход, и если хорошо реализованная и контролируемая модель может увеличить процент правильных диагнозов при первичном осмотре с 50% до 67%, то это реальная клиническая разница.
Вопрос, который я себе задаю, более неудобен: учитывая, что данные уже указывают на эту пользу, насколько долгим должен быть институциональный путь, прежде чем системы здравоохранения начнут относиться к этому серьезно? И кто определяет это время: лаборатории ИИ или медицинская система?
Похожие новости в рубрике «Технологии»
Все материалы →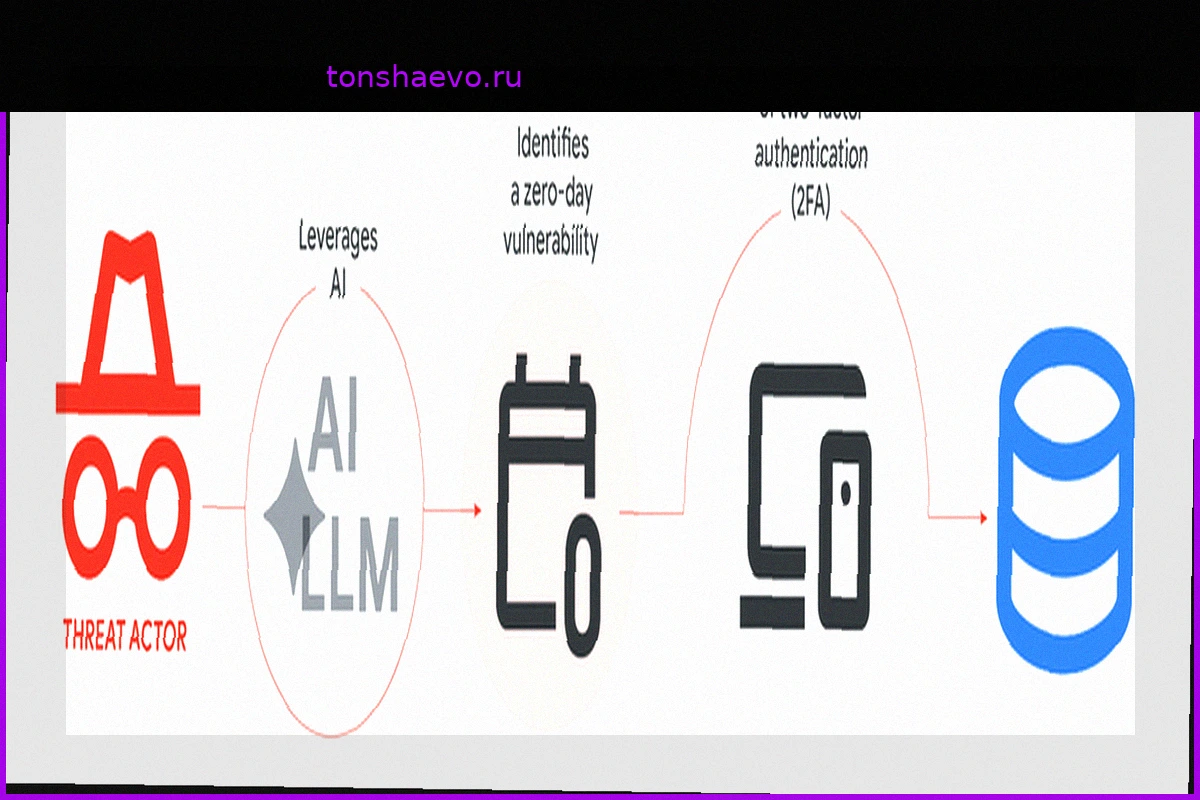
ИИ и кибербезопасность: Первый эксплойт "нулевого дня" и реальность Google
Недавно Google опубликовала информацию о событии, которого многие ожидали, но никто не хотел быть первым, кто его подтвердит: преступная группировка использовала искусственный интеллект для разработки эксплойта "нулевого дня" (ранее неизвестной уязвимости программного обеспечения), который был

LG UltraGear evo GM9: Первый 27-дюймовый 5K Hyper Mini LED Монитор
Компания LG представила UltraGear evo GM9 — революционный 27-дюймовый игровой монитор, ставший первым в мире с технологией 5K Hyper Mini LED. Этот высокопроизводительный дисплей выделяется благодаря впечатляющим характеристикам: 2304 зоны затемнения, обеспечивающие глубокий контраст, и